近日,yl6809永利集团2023级硕士生张钰洋撰写的论文被第34届USENIX安全研讨会(The 34th USENIX Security Symposium 2025)录用。
论文题目为“USD: NSFW Content Detection for Text-to-Image Models via Scene Graph”(《USD:基于视觉场景图的Text-to-Image模型违规内容检测》),指导老师为yl6809永利集团汪润副教授(通讯作者)、王丽娜教授,与新加坡南洋理工大学Kangjie Chen博士、新加坡国立大学Yihao Huang博士合作完成。yl6809永利集团2022级本科生姜旭东、温佳慧、金意辉和2022级硕士生梁子游参与了该成果的研究工作。
近年来,以OpenAI的GPT-4、DALL·E以及Google的PaLM为代表的多模态文生图(Text-to-Image, T2I)大模型快速发展,用户通过简短的文本输入即可生成高质量的图像、视频或文字内容。然而,现有研究与实践表明,当用户输入具有诱导性的文本提示或者输入的文本语义较为模糊、容易引发歧义时,模型可能生成不适宜(Not-Safe-For-Work,违规内容)的内容,这些NSFW数据的非法传播或交易,严重违反法律法规和社会道德规范,危害网络环境。
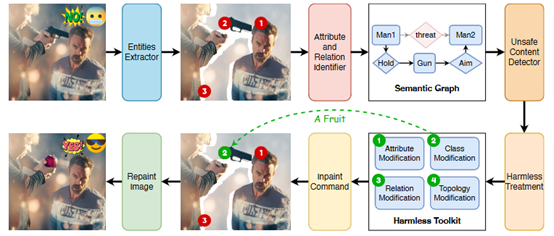
图1 面向AIGC的违规内容检测与修复框架概览
针对上述安全威胁,现有的防御方法主要通过CLIP(Contrastive Language-Image Pre-Training)等模型对图像进行基于图像全局像素特征映射与分类展开对违规图像的检测,然而其在应用中面临检测粒度不够细致、语义理解能力发挥不足、场景适应代价高昂等挑战,无法有效识别存在带有动作倾向的引导式NSFW内容(如胁迫、暴力伤害等)。为了应对以上挑战,作者提出基于视觉场景图的文生图大模型违规内容检测方法,首先从视觉语义角度对现有违规图像进行深入分析,从“实体-属性-关系”角度重新挖掘了AIGC生成违规内容的本质特征,并提出违规语义存在的三种元场景。针对这三种元场景上的内容合规审计需求,作者提出了一个全新的违规内容检测与修复框架如图1所示,设计了面向AIGC图像场景图提取方法以及面向视觉语义场景图的内容安全检测方法。实验结果表明,所提出的方法具备良好的检测准确率、场景迁移性。与现有的检测器相比,该论文所提出的检测器对违规内容的检测F1值达到了95.52%优于目前最先进的检测技术;该方法对不同场景具有很强的迁移能力,通过少样本即可完成检测器在不同应用场景下的有效迁移,其F1值达到了82.10%,显著高于目前最先进的检测技术。在此基础上,作者进一步提出细粒度违规内容无害化技术,该项技术针对三种元场景提出四种无害化工具,配合图像修复技术,实现了对违规内容的精确无痕修复,在保持同样的有害语义擦除效果的同时,保持了76.34%的SSIM相似度,显著高于目前最先进的修复技术。该项成果为AIGC安全检测领域提供了新的实用性解决方案,为防止人工智能生成技术所带来的违规内容泛滥问题提供了新的解决思路。
据悉,USENIX Security于1990年首次举办,已有三十多年历史,与IEEE S&P、ACM CCS、NDSS并称为信息安全领域国际四大顶级学术会议,也是中国计算机学会(CCF)推荐的A类会议,被录用的稿件反映了网络安全领域国际最前沿的研究水平。


